交大学生推出校内恋爱匹配平台,65 道题筛选对象,算法靠谱吗?
- 2026-06-23 17:57:27
近期,上海交通大学学生自主开发的校园恋爱匹配平台 SJTU Date 上线。平台基于心理学量表设计了 65 道问题的深度问卷,每周二定时通过算法为用户匹配一名"契合"的对象,仅限交大邮箱注册。上线不到一周,注册人数超过 7000 人,首轮报名超 4000 人,最终 2400 人成功配对。
这组数字说明什么?我觉得它首先说明的不是算法多么厉害,而是需求真实存在。
这件事很快引出了一个对比:同样是"第三方介绍对象",为什么年轻人愿意接受算法派单,却抵触父母相亲?这个问题看起来是情感问题,但如果用数学工具拆解一下,会发现它本质上是一个关于信息、效用与自主性的决策问题。
二算法匹配到底在做什么
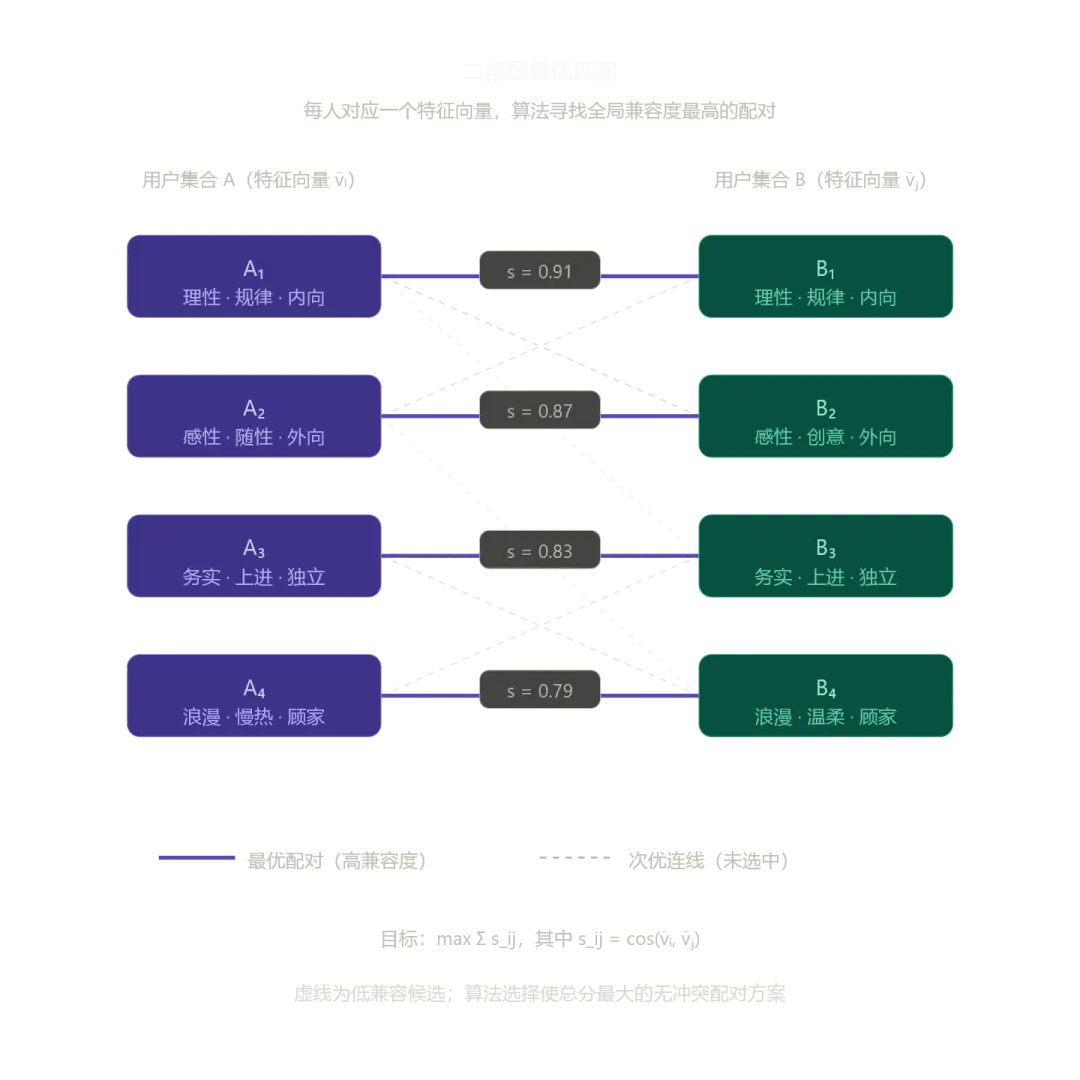
恋爱匹配在数学上是一个二部图最优匹配问题。设男性集合 ,女性集合 ,每对 之间存在一个"兼容度"分数 。
算法的目标是找到一个匹配 ,使得总体兼容度最大化:
同时满足每人最多被匹配一次的约束。这是一个经典的指派问题(Assignment Problem),可以用匈牙利算法在 时间内精确求解。对于 7000 人规模,计算上完全不是瓶颈。
真正的瓶颈在于: 怎么算。
基于内容过滤的模型
SJTU Date 的问卷本质上是在构造每位用户的特征向量,然后用某种相似度指标(余弦相似度最常见)来估算兼容度:
这是推荐系统里的基于内容的过滤(Content-Based Filtering),是一种直接、透明、可解释的方法。
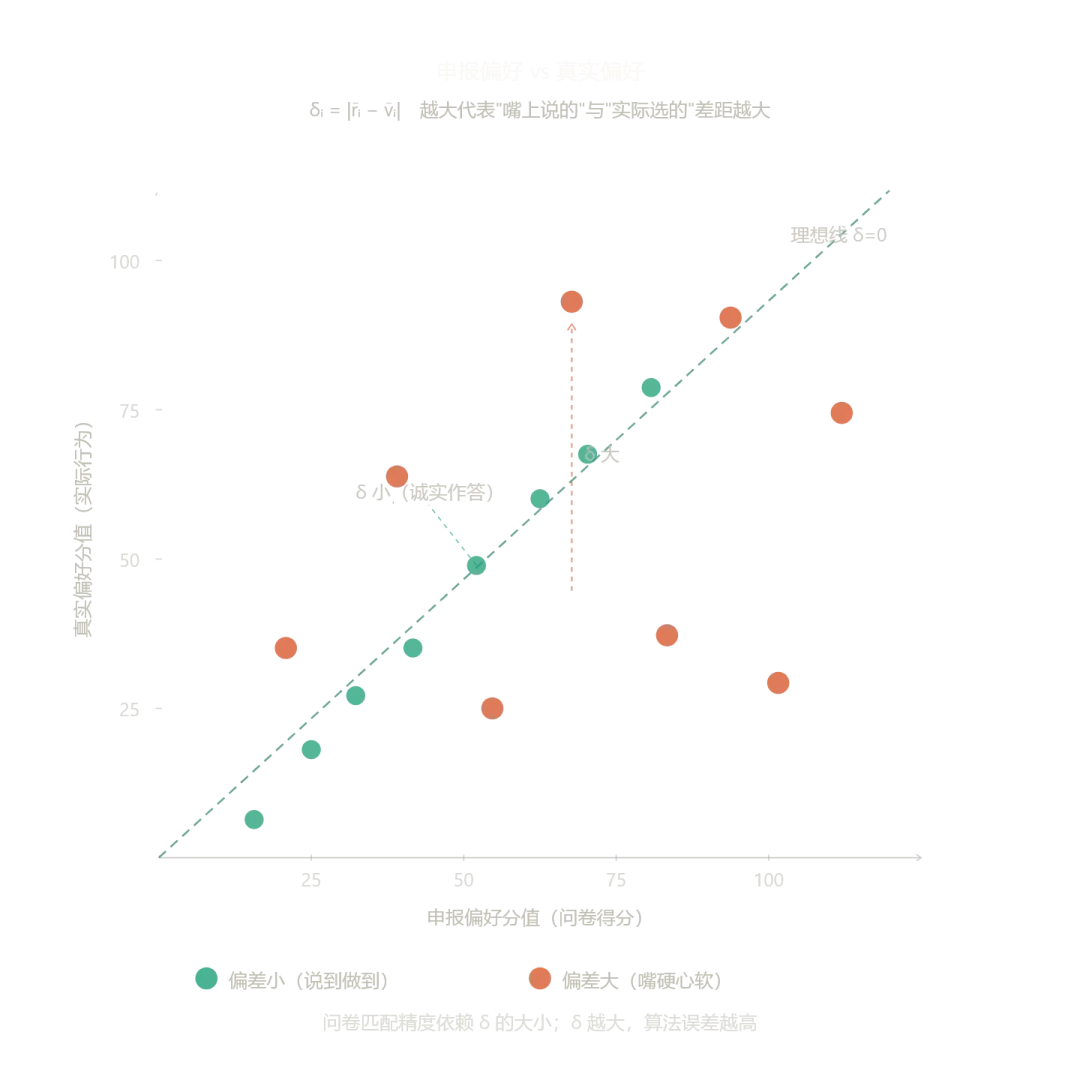
问题在于:向量 采集的是用户自己申报的偏好,而非真实行为偏好。
行为经济学里有一对概念:stated preference(申报偏好) 与 revealed preference(显示偏好)。前者是"你说你想要什么",后者是"你实际选择了什么"。两者之间往往存在系统性偏差。
设真实偏好向量为 ,申报偏好向量为 ,偏差定义为:
当 较大时,用余弦相似度算出的 与真实兼容度之间的误差也会随之放大。更麻烦的是, 对用户本人也是不透明的——你并不清楚自己真正想要什么。
2017 年,心理学家 Samantha Joel 等人在《Psychological Science》发表研究,用机器学习分析大量速配约会数据,得出结论:算法能预测"谁总体上更受欢迎",但几乎无法预测两个特定的人之间是否会产生吸引力。 换句话说,影响配对成功的因素中,有相当一部分是交互涌现的,无法从个体特征向量中单独预测。
算法真正降低的是什么成本
如果算法匹配精度有限,它的实际价值在哪里?
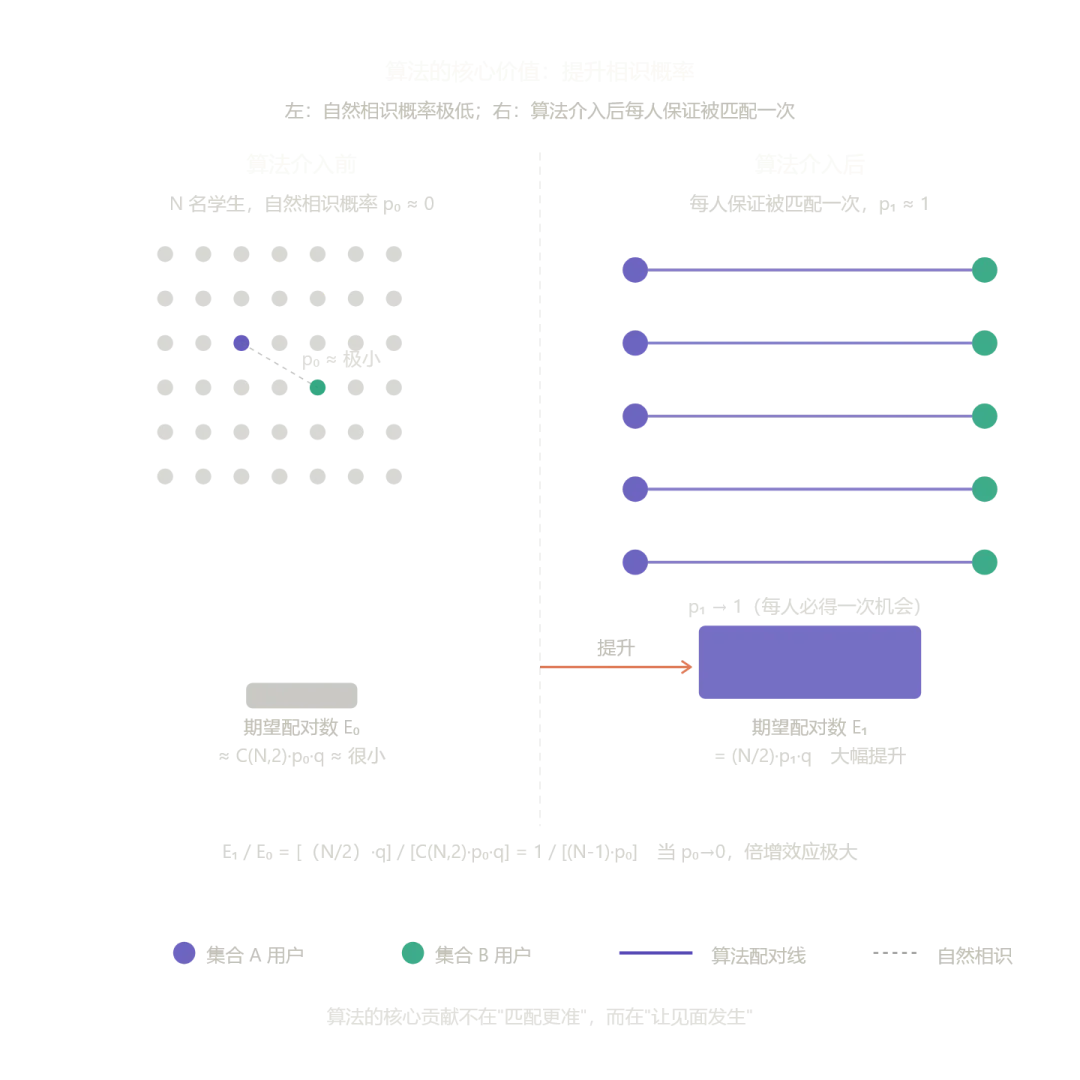
用一个简单的期望效用框架来看。假设一所高校有 名学生,两人之间自然相识的概率为 (极小)。算法介入后,相识概率提升为 (通过"派单"强制建立第一次接触)。即便后续转化率 (从相识到恋爱)不变,总配对数的期望值也从:
提升到:
在交大这种场景里, 极低——学业压力大、社交场合有限、主动搭讪的心理成本高。算法做的事情是把 从接近零拉到接近一(每人保证被匹配一次),这才是它最核心的贡献,而不是精确预测谁和谁最配。
系统派单 vs 父母严选,比的不是准确率
把上面的分析用来回答原问题:两者谁更好?
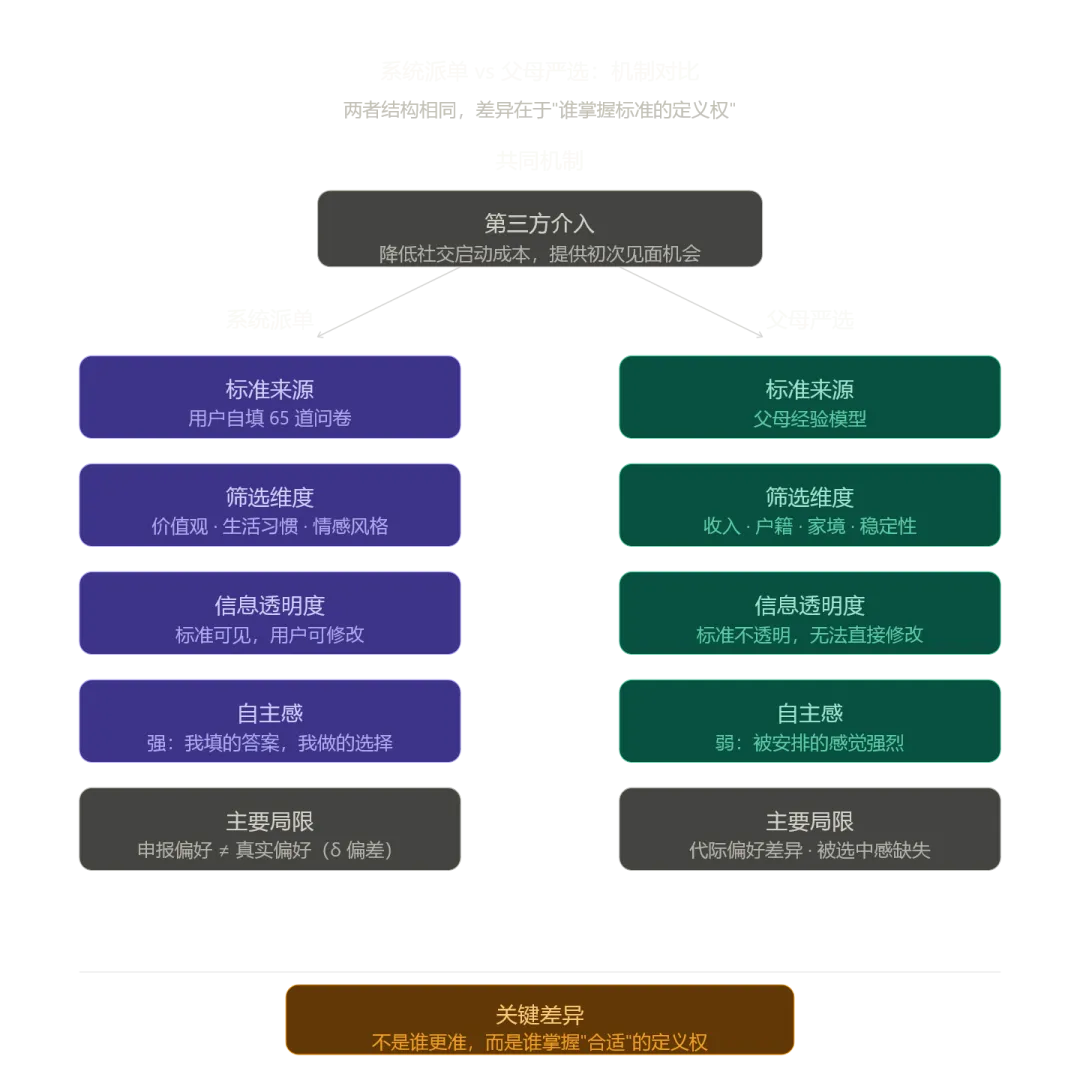
从匹配逻辑看,两者的结构惊人相似:都是第三方收集信息、建立标准、提供候选人,然后降低当事人的社交启动成本。差异不在于方法,而在于以下两点。
第一,标准的所有权。 算法使用的是你自己填写的 65 道题,父母相亲使用的是他们积累的经验模型(收入、户籍、家庭背景)。前者让你觉得"我在做选择",后者让你觉得"我在被安排"。这种感受差异不是理性计算,而是自主性需求在起作用。行为科学里有大量证据显示,哪怕选择结果相同,人们在自主参与的情况下满意度更高、归因也更积极。
第二,信息的透明度。 算法的标准可以被你看见和修改(你自己填的问卷),父母的标准往往不透明,且你没有直接的修改权。这使得年轻人在面对父母相亲时感受到的不只是"不准确",还有"不被理解"。
所以,年轻人选择算法、拒绝父母介绍,与算法是否真的更准确关系不大,更多是对自主性的追求和对信任机制的选择。
算法能做什么,做不到什么
SJTU Date 的出现让人想到一个更大的问题:如果我们把恋爱看成一个优化问题,它的目标函数是什么?
这里有一个根本性的困难。优化问题需要一个明确的目标函数,但恋爱关系的"好"是一个随时间演化、被双方共同定义的量,而不是一个固定的标量。你在 t=0 时刻填写的问卷,描述的是彼时的你;而关系的质量往往在 t=T(几个月、几年后)才能被评价。这两个时间点上的你,很可能偏好差异相当大。
用更直白的话说:算法解决的是"第一次见面"的问题,而不是"在一起"的问题。
这并不是在否定 SJTU Date 的价值。在一个高度内卷、社交场合稀少的工科校园里,能制造出 2400 次本来不会发生的见面,这件事本身就有意义。剩下的事情,需要两个具体的人去完成,算法帮不了。
网友的讨论里有一条评论说得很到位:算法给了一个理由,"不是我主动搭讪的,是系统分配的"——这句话把社交启动的心理负担降低了一个数量级。
从这个角度看,SJTU Date 的核心产品不是匹配算法,而是一个降低社交启动成本的制度设计。65 道题和算法,是这个设计的技术外壳;真正的内核是:给在效率文化里长大的年轻人,提供一个开口说话的理由。
还有一个值得警惕的地方。算法终究是在用一套"标准"来定义"合适",而这套标准是由平台(以及用户的自我认知)共同塑造的。当越来越多的初次见面经由算法发生,我们定义"合适"的能力会不会随之萎缩?这个问题没有答案,但值得思考。
一个校园恋爱平台,折射出的是一代人的社交困境和自主意志。65 道题能过滤掉明显不合适的人,但"来不来电"这件事,从来不在问卷的射程之内。
算法背后是需求,也是人心。而人心,目前还没有哪套公式能完整表达。
下面推荐我的新书《巧用DeepSeek进行数学建模》,对建模和AI使用的朋友们不要错过!

